




導讀:2023年10月20-21日,以“智能涌現 生成未來”為主題的第二十五屆中國科協年會通用人工智能產業創新發展論壇在安徽省合肥市成功召開。歐洲科學院院士、中國自動化學會副理事長、華南理工大學教授陳俊龍受邀出席并作題為“人工智能的發展趨勢與AIGC應用的探討”的主題報告。報告聚焦工業智能與智能系統前沿,探討了人工智能賦能制造業的關鍵科學問題和重點推進內容,指出人工智能作為制造業數字化轉型的新生產工具,正催生AI for Engineering這一工程研發新范式。同時進一步探討了工業智能的內涵,并提出了工業智能前沿研究的重點內容和總體目標,即:從信息感知本質、信息理解深度和系統行為決策出發,開展跨時空感知與統一表征、多模態信息可解釋泛化認知和人機共融決策與動態博弈的基礎理論與關鍵技術研究,實現制造過程高端化、綠色化、智能化運行。
以下為報告全文。
自2009年以來,國家在物聯網、云計算、大數據和人工智能領域取得了顯著進展。這些進展得益于算力、數據和算法模型的不斷支持,以及深度學習技術的興起。此外,在2008年和2009年間,軟件和硬件領域也經歷了重大的發展,促成了近期通用人工智能的興起。
一、算力
最近,國家在通用人工智能(AIGC)領域的發展受益于算法、算力和數據的顯著提升。為了提供企業強有力的算力資源,政府在2022年統籌啟動了東數西算工程。這個工程概念類似于早期的南水北調和西電東送工程,旨在建立8個關鍵樞紐點,分布于長三角、珠三角、寧夏、貴州、內蒙等地,這些樞紐點也 配置了數據中心的重要角色。目前東數西算工程正在進行大規模建設。這些舉措不僅在土建工程、軟件工程和信息技術等領域對國家產業鏈的發展產生了積極作用,而且為能源利用和雙碳減排工程貢獻了一份力量,并滿足了中小企業對大規模數據資源的需求。合肥市也在呼應該計劃在組建算力上扮演著非常重要角色。
英偉達公司今年5月宣布了"Hopper"計劃,旨在分析當前的GPU技術。該計劃旨在推動GPU技術的發展,以滿足不斷增長的計算需求,尤其是在人工智能和科學計算領域。計劃的一部分包括推出基于新架構的GPU產品,以提供更高的性能和效能。這將有助于滿足日益增長的計算要求,幫助研究人員、科學家和工程師在各個領域開展創新性的工作。該計劃啟動時,國內尚未受到美國的限制,但它給我們帶來了一系列未來發展的思考。回顧早期CPU技術,特別是在大型語言模型的訓練方面,以ChatGPT為例,實現這一目標需要巨大的計算資源。然而,借助GPU計算中心資源,成本約為40萬美元,能源消耗也僅相當于傳統CPU的約1/8。若投入1000萬美元,我們能夠實現4倍LLM(Large Language Model)大語言模型的規模。進一步考慮到能源消耗,我們甚至可以實現高達150倍LLM的容量,如圖1所示。
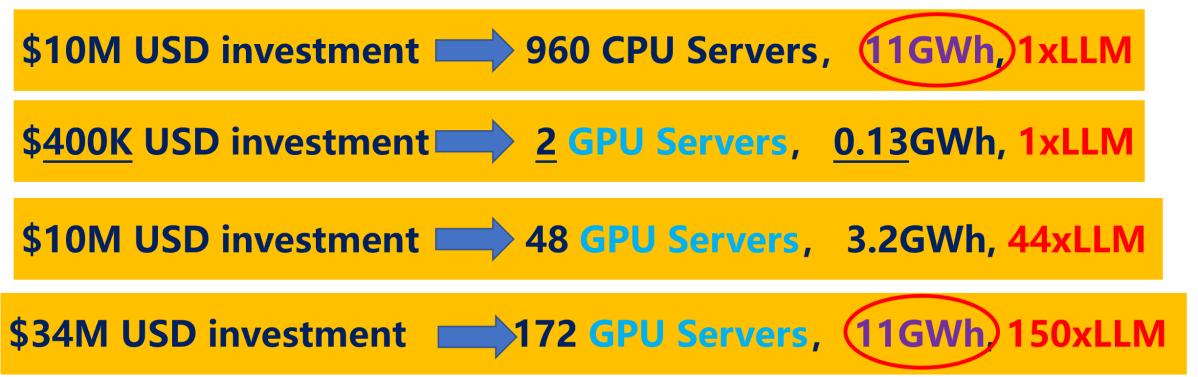
圖1 CPU/GPU資源對比
這引發了深刻思考,若我們擁有足夠的計算能力和資源,大型語言模型規模有可能增加到150倍。隨著算力和數據更深度的協同作用,未來通用人工智能預計會變得更加智能,這意味著通用人工智能將在各行各業中發揮作用,為各種問題提供解決方案。
目前國內正在積極研究除了GPU之外的其他算力支持大型語言模型的方案,其中包括MPU(混合處理器單元),NPU(神經元處理單元),和TPU(張量處理單元),如圖2所示。最近,研究人員開始探討如何利用量子計算來克服DPU(深度處理單元)所面臨的局限,這引起了廣泛的討論。谷歌很早之前就在進行TPU和MPU的研究,而現在,阿里巴巴、寒武紀等公司也在積極研究這些新的計算架構,這些努力有望突破目前GPU所面臨的限制。

圖2 CPU、GPU、TPU方案
二、數據
數據在大型語言模型中起著關鍵作用,一個大型語言模型的性能和智能程度與訓練數據的質量密切相關。因此,數據的重要性不可忽視。國家在2021年底便開始建立數據聚集和管理系統,不僅著重管理整個數據生命周期,包括數據來源、存儲、處理、交換和傳輸,并且實施數據分析等級的分類處理,以確保數據在未來如何進行去標識化和去敏感化處理,如圖3所示。這一舉措強調了數據的關鍵性,以確保數據在各個方面的安全和有效管理。
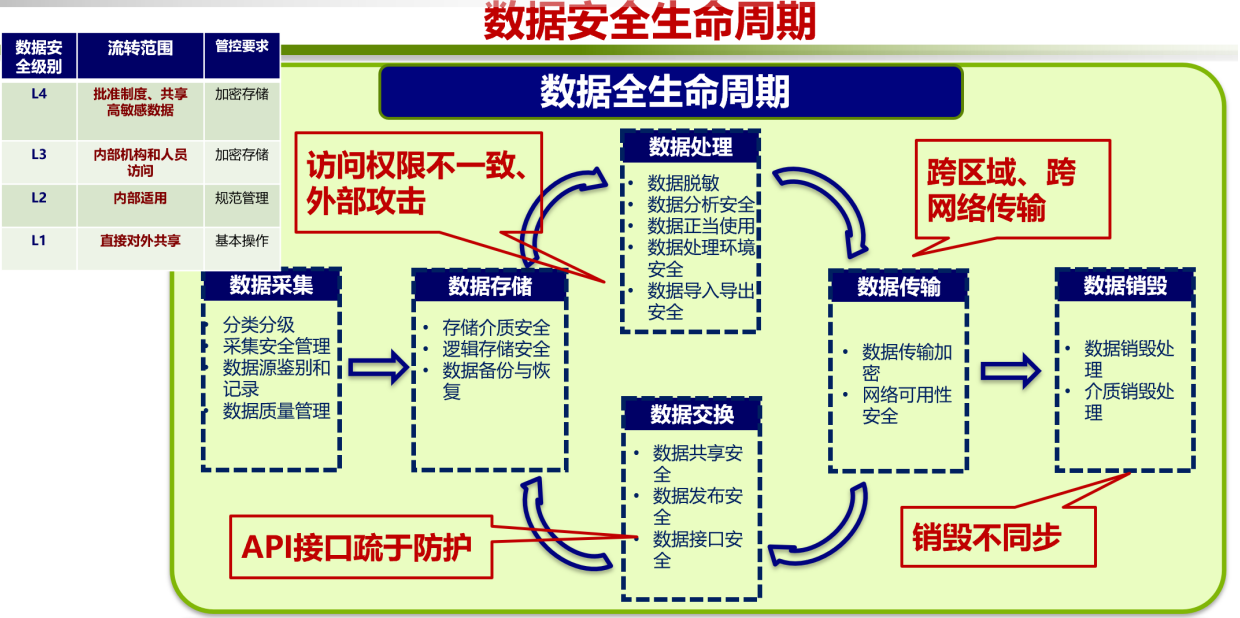
圖3 數據安全生命周期
同時,國家在各個省市紛紛設立數據交易所,如在廣東和深圳同時建立了數據交易所,這些交易所是由省市共同支持和發展的。未來,各行各業的數據可以像煤氣、水電一樣進行交易。這意味著在模型訓練時,不再局限于使用公共數據,而可以利用交易的數據進行模型訓練,這是國家在數據領域取得的重要突破,將為人工智能的發展提供更多的數據資源和可能性。
三、模型與算法
大型模型的概念首次出現在2015年和2016年,由于生成式模型尚未嶄露頭角,所以當時還沒有引起廣泛的關注。當時OpenAI組成的GPT-3在當時尚未加入Chat功能,當時也沒有類似文心一言、通義千問,訊飛的星火等大模型。從今年開始這些模型開始逐漸涌現,如圖4所示。大型模型的主要特點之一是其擁有千億級參數的規模,同時希望能夠通過標注的小樣本來進行模型訓練。

圖4 國內外語言大模型
最近,網絡上已經發布了大約80個具有超過10億參數的模型,然而,目前只有11個模型通過了國家的認證 。這表明不同機構對于這些大型模型的價值評估各有不同。總體而言,中美兩國的大型模型已經占據了全球的80%份額,這引發了國內各行各業都希望構建自己的大型模型的熱情。然而,通用大型模型的構建相對困難,因為它需要龐大的計算資源支持。因此,國內正在進行所謂的“百模大戰”,旨在建立各個領域的小型專用大型模型,以滿足不同行業的需求。這凸顯了大型模型在國內的廣泛應用和重要性。
當前最主要的問題國內大型模型的計算能力仍然高度依賴國外的生態系統,包括依賴微軟、英偉達等公司的產品以及算子庫。盡管國內擁有華為的昇騰系統算子庫,但仍然需要與用戶合作開發。這個問題涉及的領域非常廣泛,最主要的挑戰是如何改變國內顯卡的生態系統。國外的生態系統已經形成了全球性的格局,而要改變國內生產的顯卡的生態系統相對更具挑戰性。國內擁有兩三家顯卡生產商,如曙光、寒武紀等,但由于缺乏與生態系統的深入了解,難以推廣和普及。未來,這些企業需要積極探討如何構建生態系統,以改變國際局勢并打破依賴國外生態系統的現狀。
在構建大型模型時,需要考慮兩個關鍵要素。首先,數據的規模對于模型構建速度至關重要,大型數據集需要更多的時間來建立模型,所以快速構建準確有效用的模型至關重要。其次,也應考慮在模型構建后如何快速應用增量數據進行更新。這方面的挑戰在于涉及大量數據,因此更新過程可能相對復雜。目前,我們正在探索邊緣端的實時模型更新方法,使得在模型訓練完成后,客戶端可以實現隨時更新,而不必將模型返回到原始大型模型進行批量更新。寬度學習在這一領域發揮了重要作用,尤其是對于實時增量數據的更新。
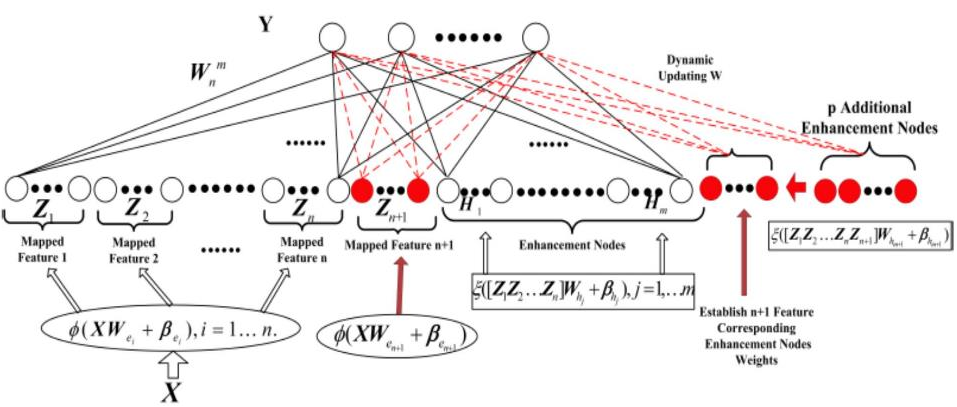
圖5 寬度學習系統
在算力和模型都達到要求滿足時,算力冷卻便成為了一個難題。現在,算力冷卻系統采用了多種方法,包括風冷系統、液冷系統以及浸沒冷卻。在浸沒冷卻方面,我們建立了一個模型,以調整化學成分,將冷卻效率最大化。這種方法可以使PUE值降至1.07,低于國家規定的水平,并且此種冷卻形態需要更少的空間。相比于傳統的大型計算機柜,這種方法在效率和空間利用方面都有顯著的優勢。

圖6 基于浸沒式液冷技術的高性能算力解決方案
四、AIGC對公司生態的影響
近期人工智能研究公司OpenAI推出的聊天機器人模型CHAT-GPT不斷出圈,繼2019年向OpenAI注資10億美元之后,微軟與OpenAI的合作進入第三階段。據Semafor引知情人士報道,微軟以290億美元估值,向OpenAI 投資100億美元,一切均指向人工智能模型的新范式“生成式AI模型(Generative Model)”。決策式AI模型(Discriminant Model)是根據已有數據進行分析、判斷、預測,典型應用為內容的智能推薦(短視頻)、自動駕駛等;而生成式AI更強調學習歸納后進行演繹創造,生成全新的內容,本質是對生產力的大幅度提升和創造,已催生了營銷、設計、建筑和內容領域的創造性工作,并開始在生命科學、醫療、制造、材料科學、媒體、娛樂、汽車、航空航天進行初步應用,為各個領域帶來巨大的生產力提升。
在AIGC方面,來談談數字人及人機交互的應用。目前,為解決人體大健康領域的問題,我們獲批的教育部的健康智能和數字 平行人工程中心正在探討在數字世界與真實的物理世界里人機交互的問題 。。目前已經初步開發了數字人,使其能夠進行對話并相互了解,數字人之間也可以互相交互,而且數字人可以在現實空間與真實人進行互動。我們的團隊正在致力于情感識別及在數字世界與物理世界人體健康監控及交互的研究。。
生成式人工智能對公司生態的影響最大的是互聯網公司。現在,如果公司能夠熟練使用生成式人工智能來編寫代碼和開發嵌入式應用,未來的公司將變得更小而更精致。這將帶來更多的盈利機會,使員工有機會成為創業者或老板。他們可以迅速將生成式人工智能整合到公司中,以實現更高效的嵌入式應用。目前,國內在生成式人工智能方面仍有很大的發展空間,各種小型科學家和企業都有機會嵌入到人工智能平臺應用中,未來的創新和發展會涌現更多機會。
從產業價值角度來看,生成式人工智能可以迅速分為上游、中游和下游三個方向。上游產業涉及基礎建設,下游產業則涉及應用,而中游產業在各個行業中起到樞紐作用。初創公司在這一領域屬于中小型,但未來可能成為龍頭企業,這將產生巨大的產業價值。在實際生產應用中,還沒有大規模采用生成式人工智能的情況,主要是因為大部分應用仍然依賴傳統的專用小型大模型,這些模型使用相對較小的計算資源進行訓練。未來,生成式人工智能將在各個領域得到更廣泛的應用,這取決于我們擁有的算力和數據基礎。
ChatGPT是AIGC目前最典型及最有名氣的平臺產品。此類的平臺它具有正面和負面兩面的影響。一方面它擴大了知識的傳播途徑,提供了便捷的信息獲取方式,個性化的服務,以及自動化客戶支持,同時還有創新應用的潛力。另一方面,其具有不準確信息和偏見傳播的風險,可能對隱私構成威脅,引發失業風險,以及可能被濫用。解決這些問題需要審查數據來源、開發偏見識別和修正技術,強化隱私法規,以及進行社會倫理和道德教育。總而言之,ChatGPT和AIGC類似技術在未來將繼續發揮重要作用,但需謹慎管理,以最大程度地提升積極影響,降低其潛在負面的影響。
